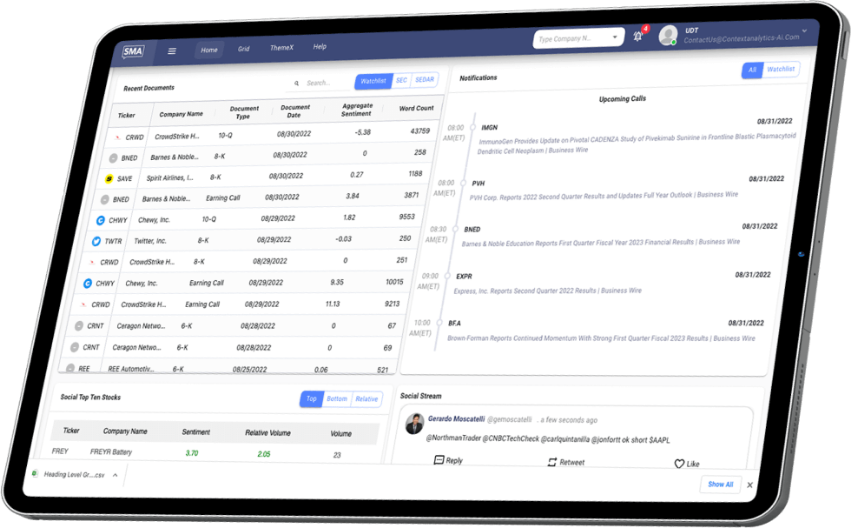
Context Analytics, Inc. differentiates through transparency. We provide our historical data, along with results related to back tested results and alpha derivation, to clients, academia, and interested firms.
Data Sources
Latest From Context Analytics
The Case for Data: An Extended Look
What began as a discussion about intraday alternative data quickly expanded into a broader conversation about AI adoption, specifically on the buy side. One of the speakers described how their firm was adopting agentic AI to automate work traditionally performed by entry-level research roles. This led to a wider discussion about AI adoption across the investment process and the industry more generally.